Creating a Web app of a ML model using Streamlit

In my previous post Language Detector using NLP , I shown you all how to create a NLP Machine Learning model to predict the language of a given text using Naive Bayes algorithm. It was a very simple NLP project and suitable for beginners. I hope you all liked it.
In this post, I will be sharing with you how to create a web app of the same model using Python's Streamlit library.
Getting started with Streamlit
Streamlit is an open-source python library that is used for creation and sharing of web apps in minutes, not weeks. Because of its ease to use nature, It is gaining lots and lots of popularity among the data science community and many developers are using it in their daily workflow. The streamlit's GitHub repos has more than 14.4k stars and 1.2k forks. Under the hood, it uses React as a frontend framework to render the data on the screen. So, React Developers can easily manipulate the UI with few changes in the code.
For more info on streamlit, refer to it's official website
Installing Streamlit
To use streamlit, first we need to install it. Use the following code to install it easily
pip install streamlit
For more info on how to install, refer it's official documentation
Running Streamlit for the First Time
You can run a demo app that comes with the Streamlit package by running the following command into a terminal
streamlit hello
This command will start a demo Streamlit app. Open the web browser and enter the URL shown in your terminal. The running app will look something like this.
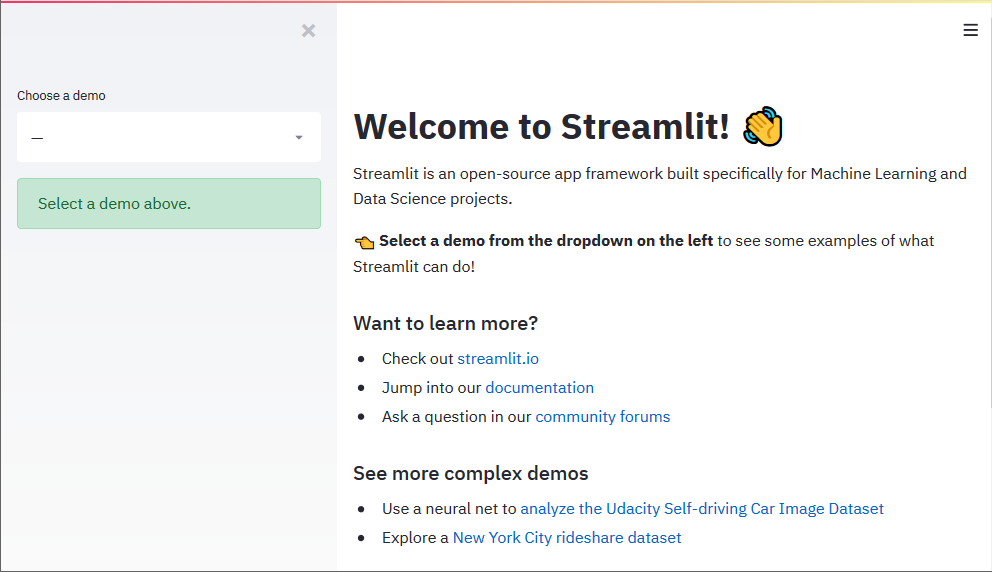
You can select any demo from the page and see how things work
Type [Ctrl]+[c] into the terminal stop the Streamlit server.
Now that we have got our hands a little dirty, let's build a simple Steamlit Web App.
Creating a simple Streamlit Web App
Follow the following steps to build a simple web app:
- Import all the required libraries in our program
import pandas as pd
import numpy as np
import pickle
import re
import streamlit as st
from PIL import Image
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.preprocessing import LabelEncoder
- Import our model and count vectorizer, both of which we pickled after creating the final model.
#Pickled model
pickle_in=open('language_predictor.pkl','rb')
language_predictor=pickle.load(pickle_in)
#Count vectorizer
cv_pickle=open('vectorize.pkl','rb')
cv=pickle.load(cv_pickle)
- Create a label encoder for encoding and reverse encoding our languages
#label encoder
le = LabelEncoder()
- Now, lets write our
predictionfunction
We will load the dataset, encode the languages and clean the input text using some basic regex. The code for which is
def lang_predict(text):
# loading the dataset
data = pd.read_csv("Language Detection.csv")
y = data["Language"]
# label encoding
y = le.fit_transform(y)
#Cleaning the input text
text = re.sub(r'[!@#$(),\n"%^*?\:;~`0-9]','', text)
text = re.sub(r'[[]]', '', text)
text = text.lower()
data = [text]
Now, we will convert the text (for which we need to predict the language) into bag of words model i.e. vectors and pass the vector to model for prediction.
# converting text to bag of words model (Vector)
x = cv.transform(data).toarray()
# predicting the language
lang = language_predictor.predict(x)
Than, we will inverse transform the predicted result to find the language of the input text and return the result.
# finding the language corresponding the the predicted value
lang = le.inverse_transform(lang)
# return the predicted language
return lang[0]
The final predict function looks something like this:
def lang_predict(text):
# loading the dataset
data = pd.read_csv("Language Detection.csv")
y = data["Language"]
# label encoding
y = le.fit_transform(y)
#Cleaning the input text
text = re.sub(r'[!@#$(),\n"%^*?\:;~`0-9]','', text)
text = re.sub(r'[[]]', '', text)
text = text.lower()
data = [text]
# converting text to bag of words model (Vector)
x = cv.transform(data).toarray()
# predicting the language
lang = language_predictor.predict(x)
# finding the language corresponding the the predicted value
lang = le.inverse_transform(lang)
# return the predicted language
return lang[0]
- Now, lets start with building the web app using streamlit
Import streamlit in your app's app.py file
import streamlit as st
After importing it, write a function which defines the properties of the web app page.
We are defining the page title using following code
def main():
st.title("Language Predictor")
Than we are defining some basic styling info about our web page like its backgroung color, style-color, some text to display etc. using the following code
html_temp = """
<div style="background-color:tomato;padding:10px">
<h2 style="color:white;text-align:center;">Language Predictor using NLP</h2>
</div>
"""
Than we are defining the input colunm for our ML model fro which we will get the text to predict and input it to our predictor.
text=st.text_input("Text to Predict","Type Here")
Than we are building the submit column and how it will function. We will create a Predict button, which user will press once some text is writte in the given space. On pressing of this button, our program will take the input, do some preprocessing (if any is defined in the predict function) and pass it to the model for prediction. It will also show the model output in the output section.
result=""
if st.button("Predict"):
result=lang_predict(text)
st.success('The given text is written in {}'.format(result))
We have also created an Aboutbutton which shows some basic info about our webpage.
if st.button("About"):
st.text("Predicting Language of a given text using NLP")
st.text("API built with Streamlit")
The complete function looks something like this
def main():
st.title("Language Predictor")
html_temp = """
<div style="background-color:tomato;padding:10px">
<h2 style="color:white;text-align:center;">Language Predictor using NLP</h2>
</div>
"""
st.markdown(html_temp,unsafe_allow_html=True)
text=st.text_input("Text to Predict","Type Here")
result=""
if st.button("Predict"):
result=lang_predict(text)
st.success('The given text is written in {}'.format(result))
if st.button("About"):
st.text("Predicting Language of a given text using NLP")
st.text("API built with Streamlit")
Our final app.py file looks something like this
import pandas as pd
import numpy as np
import pickle
import re
import streamlit as st
from PIL import Image
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.preprocessing import LabelEncoder
#label encoder
le = LabelEncoder()
#Pickled model
pickle_in=open('language_predictor.pkl','rb')
language_predictor=pickle.load(pickle_in)
#Count vectorizer
cv_pickle=open('vectorize.pkl','rb')
cv=pickle.load(cv_pickle)
def lang_predict(text):
# loading the dataset
data = pd.read_csv("Language Detection.csv")
y = data["Language"]
# label encoding
y = le.fit_transform(y)
#Cleaning the input text
text = re.sub(r'[!@#$(),\n"%^*?\:;~`0-9]','', text)
text = re.sub(r'[[]]', '', text)
text = text.lower()
data = [text]
# converting text to bag of words model (Vector)
x = cv.transform(data).toarray()
# predicting the language
lang = language_predictor.predict(x)
# finding the language corresponding the the predicted value
lang = le.inverse_transform(lang)
# return the predicted language
return lang[0]
def main():
st.title("Language Predictor")
html_temp = """
<div style="background-color:tomato;padding:10px">
<h2 style="color:white;text-align:center;">Language Predictor using NLP</h2>
</div>
"""
st.markdown(html_temp,unsafe_allow_html=True)
text=st.text_input("Text to Predict","Type Here")
result=""
if st.button("Predict"):
result=lang_predict(text)
st.success('The given text is written in {}'.format(result))
if st.button("About"):
st.text("Predicting Language of a given text using NLP")
st.text("API built with Streamlit")
if __name__== '__main__':
main()
Running the web app in local
Once the complete code is written, write the requirements.txt file also, which will have all the libraries which we used in our app.py file along with their version also, so nothing breaks in future. It will be used later when we will deploy our web app on Heroku platform.
requirements.txt
pandas==1.2.0
streamlit==0.74.1
numpy==1.19.2
Pillow==8.2.0
scikit_learn==0.24.2
regex==2020.11.13
After writing both app.py and requirements.txt files, in the directory where both the files are stored, run the following code:
streamlit run app.py
It will run our web app in local and give us a link. On clicking the link, we will be redirected to the local host where the app is hosted and we can test it there locally.

Once you open the link given, we will be redirected to our web app, which looks something like this:
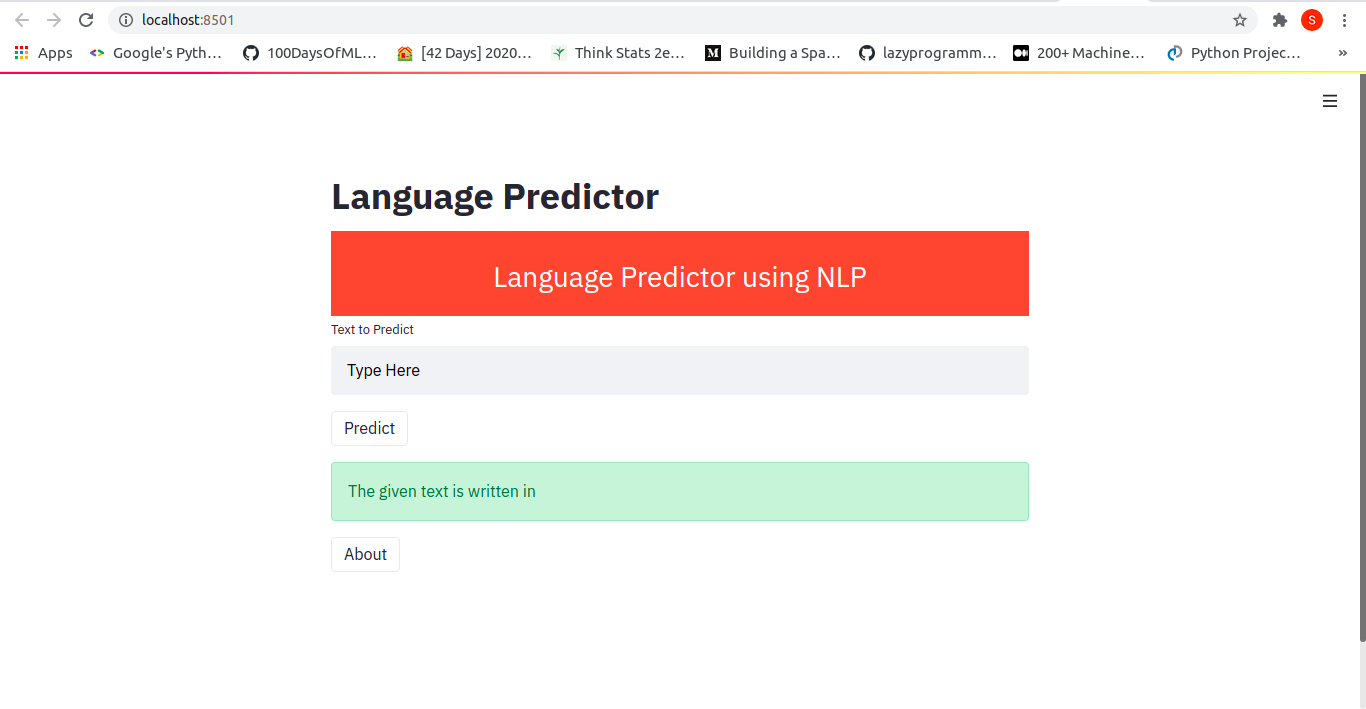
Now, we can input some text and see the prediction. Some examples are:
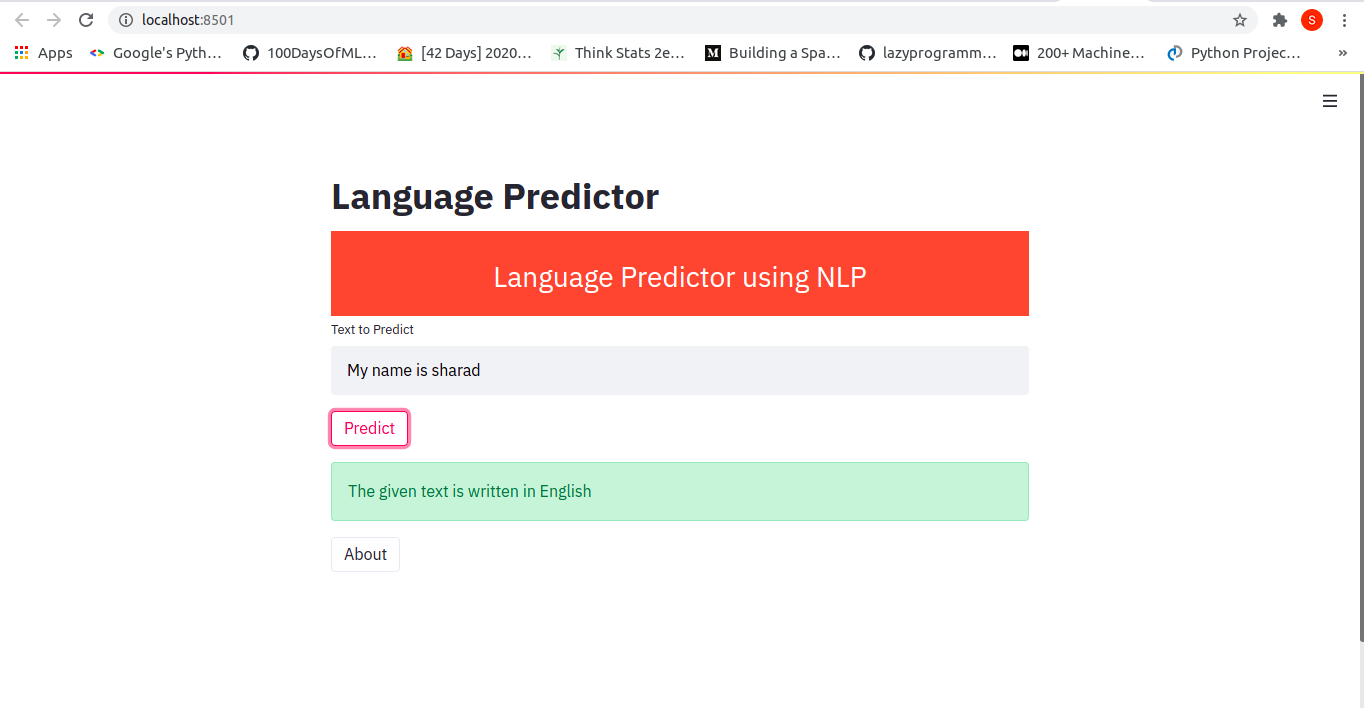
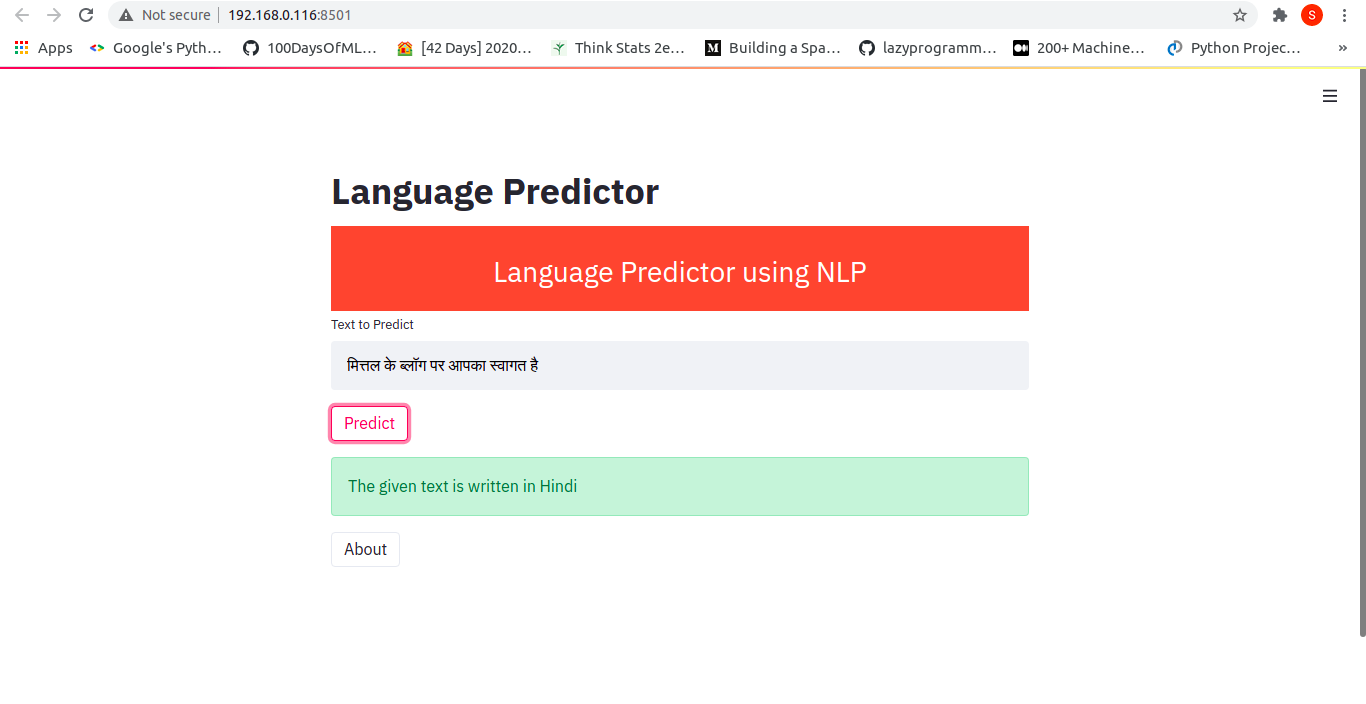
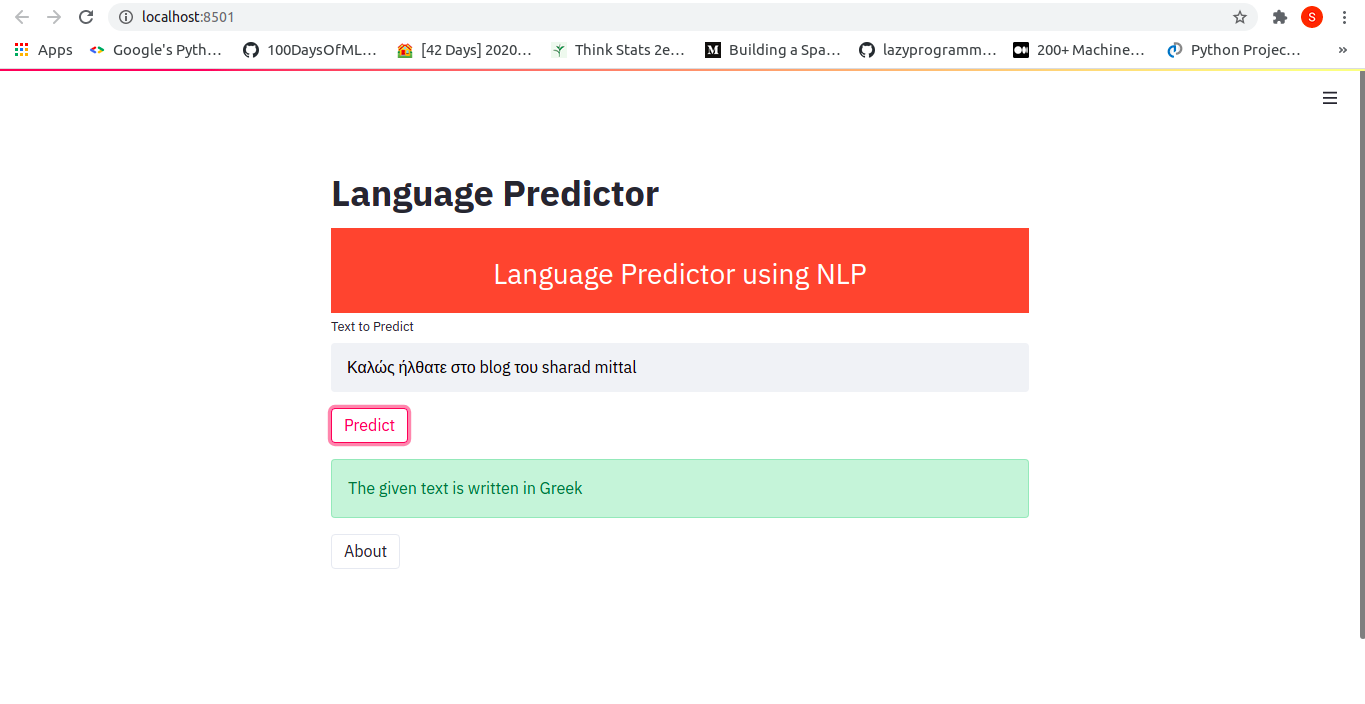
That's all about creating a web app using streamlit.
That's it! simple, isn't it? Hope this tutorial has helped.
In my next post, i will be writing about how we can host the web app on Heroku platform
You can play around with the library and explore more features
You can find all the code at my GitHub Repo. Drop a star if you find it useful.
Thank you for reading, I would love to connect with you at LinkedIn.
Do share your valuable feedback and suggestions!


